



この記事はJim Holmesによるゲスト投稿です。
テストにコードカバレッジを活用する
私が思うに、探索的テストはテスト対象のシステムにどんなリスクがあるかを理解しておこなう場合に、最も効果があるでしょう。私はリーン原則のかなりの信奉者で、リーン原則の言う「ムダ」の概念には非常に共感しています。そんなわけで、私は探索的テストでどこに労力を集中すべきかがよくわかるよう、システムで現在どんな自動テストが行われているかを把握するというやり方を愛しています。
このとき、長年にわたって便利に使っているツールがコードカバレッジメトリクスです。コードカバレッジは、コード全体のうち自動テストで実行された部分に着目し、どこがカバーされたか、あるいはされていないかを示します。通常、カバレッジは大きな部分(JARやDLLファイルなど)ごと、それから領域内のコンポーネントごと(クラス、メソッドなど)に分けて表示されます。
カバレッジメトリクスはビルドパイプラインの一環としてSonarQube、NCover、dotTESTやJtestなどのツールを実行することによって生成されるのが一般的です。Visual Studioや前述のNCover、dotTESTなどのツールを使って、開発者/テスターのシステムでローカルにカバレッジメトリクスを生成することもできます。

コードカバレッジ情報は、テストおよび計測に利用しているツールセットに応じて、さまざまなタイプの自動テストから生成できます。すべてのコードカバレッジツールは単体テストと連携できます。大半のツールは統合/サービス/APIテストと連携でき、多くはユーザーインターフェイス(UI)レベルの自動機能テストのカバレッジも取得するよう設定できます-WebDriverのUIテストのカバレッジを生成する場合がよい例です。
たとえば、MicrosoftのVisual Studioのドキュメントからとった次の画像は、Mathコンポーネント内のコードブロックを表示しています。SquareRootメソッドの一部はテストによってカバーされていますが、カバーされていない部分もあります。

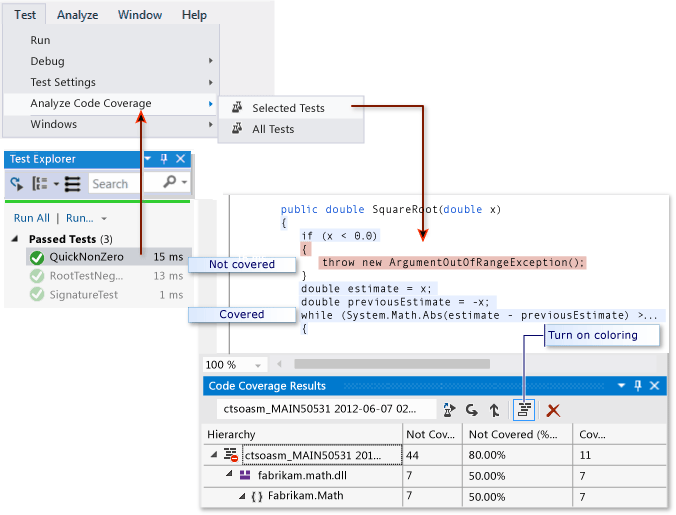
カバレッジは間違った使い方をされるひどいメトリクスであることもあります。カバレッジは、ブロックをカバーするテストが本当に「良い」テストかどうかについては何も示唆しません。可能性としては、ある自動テストでコードブロックが100%カバーされるが、テストは単にブロックを呼び出しているだけで、ブロックが期待どおり動作しているかについては、実質的なアサーションを何もおこなっていないということもあり得ます。
この点は心に留めておく必要がありますが、それでもコードカバレッジはテスターにとって、システムのうちリスクの高い、注目すべき部分を探すための良い指針となります。コードカバレッジは、テストですでに十分にカバーされているセクションを避けるのにも役立ちます。
私は2つの方向からコードカバレッジに注目します。まず、上で述べたような技術的側面です。それには、ビルドレポートまたはローカル開発環境で収集されたメトリクスを見ます。次に、私にとってはこちらのほうが重要なのですが、チームとコラボレーションして「どのように」テストが行われているかを理解するのに時間をかけます。
コードカバレッジの技術的側面からは、特定のデータを調べる必要があるか、それともすでにカバーされているなら避けるほうがいいのかがわかります。 (興味を持たれたら、POCO、POJO、DTOで検索して調べてみてください)。
- 自動テストですべての境界条件がカバーされている?
- すばらしい!それなら、探索的テストセッションで見る必要はないわけです。
- 特定の部分のコードカバレッジが特に低い?
- ひょっとすると、その部分はあまり重要ではない単純なデータコンテナーオブジェクトで、高いカバレッジは必要ないのかもしれません。
コードカバレッジのコラボレーション的側面からは、調べる必要があるかもしれない、より意味のある複雑な領域がわかります。たとえば、システム間の通信、エッジケース、チームの他のメンバーが認識していないテストアプローチなどがあげられるでしょう。
自動テストでカバレッジを利用し、探索的テストへ良い影響を与えた例
ここで、何年か前に私がクライアントのチームで実際に経験したことを基に、単純化した例を使って説明しましょう。私はテスターがWebDriverを学ぶのを手助けするために招かれました。(ところで、常に重要なのは、単にWebDriverの使い方を学ぶことではなく、まず良いテストについて学んでから、良いテストプラクティスに加えてWebDriverなり他のツールなりを適用することです…)
私は、あるUIグリッドに関してチェックを自動化すべき60個のテストのリストを渡されました。そのグリッドは、製品ラインの構成情報を計算するためのものでした。グリッドはJavascriptで高度にカスタマイズされ、出力構成データを計算する式を使っていました。自動化を求められたチェックは、すべて構成データの計算を検証するものでした。
その時、チームは大々的にスキルやプラクティスの向上に取り組んでいる最中でしたから、開発者レベルでどんな単体テストがすでに行われているかを確認しようとテスターたちが考えもしなかったことを知っても、私は驚きませんでした。私たちはSonarQubeのビルドレポートを見て、テストカバレッジがどのくらいか確認しました。システムの懸案の部分について、テストカバレッジメトリクスは非常に良好でしたが、テスターは自分たちが見ているカバレッジを理解できるだけのレベルには到達していなかったのです。
これをきっかけに、開発者たちと直接カバレッジについて話をし、テスターは現在の自動テストのカバレッジを信頼するようになりました。UIレベルのテストを60個作成して計算を確かめる代わりに、私は機能を検証するテストをいくつか作成することができました。
より重要な点として、またこの記事の探索的テストというテーマに戻って言えば、開発者の作成したテストはかなり単純なものだったことがわかりました。テストでは100%のコードカバレッジが達成できていました。しかし、懸案の機能は、複数のパラメーターを使用して構成データを計算していました。開発者は複数のパラメーターが関与することに起因するバグのリスクについては認識しておらず、組み合わせテストやペアワイズテストでリスクを低減する方法についても知りませんでした。
結局、私はテスターたちとともに、探索的テストセッションを実行するのと並行して、多数のペアワイズテストシナリオの作成に時間を費やしました。複雑な相互作用を処理するときのシステムの状態に関する情報が得られただけでなく、テストシナリオの一部を開発者に提供し、自動テストカバレッジの向上に役立てることもできました。
さいごに
探索的テストは優れたテスターの時間とスキルを最大限に活用できます。コードカバレッジを理解することは、探索的テストセッションの価値を高めるすばらしい方法です。
JimはPillar Technologyのエグゼクティブコンサルタントとして、さまざまな組織のソフトウェアデリバリープロセスの改善を支援しています。Guidepost Systems のオーナー/運営者でもあり、課題に取り組んでいる組織と直接的に関わっています。1982年にアメリカ空軍に入職して以来、IT業界のさまざまな領域での経験があります。長年にわたってチームや顧客がすばらしいシステムをリリースできるよう支援してきたほか、LAN/WANおよびサーバー管理業務にも携わりました。新興企業からFortune 10企業まで、幅広い組織に協力し、デリバリープロセスを改善して顧客によりよい価値を届けられるようサポートしてきました。プライベートでは、キッチンでワイングラスを手にしていたり、Xboxをプレイしたり、家族とハイキングを楽しんだり、ギターを練習しようとしてガレージに追いやられたりしています。
(この記事は、開発元Gurock社の Blog 「Using Test Coverage to Inform Exploratory Testing」2019年5月7日の翻訳記事です。)